Natural language processing involves the reading and understanding of spoken or written language through the medium of a computer.
Natural language processing (NLP) is the relationship between computers and human language. More specifically, natural language processing is the computer understanding, analysis, manipulation, and/or generation of natural language.Natural language refers to speech analysis in both audible speech, as well as text of a language. NLP systems capture meaning from an input of words (sentences, paragraphs, pages, etc.) in the form of a structured output (which varies greatly depending on the application). Natural language processing is a fundamental element of artificial intelligence.
How Systems Interpret Language
- Morphological Level: Morphemes are the smallest units of meaning within words and this level deals with morphemes in their role as the parts that make up word.
- Lexical Level: This level of speech analysis examines how the parts of words (morphemes) combine to make words and how slight differences can dramatically change the meaning of the final word.
- Syntactic Level: This level focuses on text at the sentence level. Syntax revolves around the idea that in most languages the meaning of a sentence is dependent on word order and dependency.
- Semantic Level: Semantics focuses on how the context of words within a sentence helps determine the meaning of words on an individual level.
- Discourse Level: How sentences relate to one another. Sentence order and arrangement can affect the meaning of the sentences.
- Pragmatic Level: Bases meaning of words or sentences on situational awareness and world knowledge. Basically, what meaning is most likely and would make the most sense.
Methods Used
Tokenization
Tokenization is a way of separating a piece of text into smaller units called tokens. Here, tokens can be either words, characters, or subwords. Hence, tokenization can be broadly classified into 3 types – word, character, and subword (n-gram characters) tokenization. For example, consider the sentence: “Never give up”.The most common way of forming tokens is based on space. Assuming space as a delimiter, the tokenization of the sentence results in 3 tokens – Never-give-up. As each token is a word, it becomes an example of Word tokenization.

Stop Words
stop words are words which are filtered out before or after processing of natural language data (text).[1] Though "stop words" usually refers to the most common words in a language, there is no single universal list of stop words used by all natural language processing tools, and indeed not all tools even use such a list. Some tools specifically avoid removing these stop words to support phrase search.
Lemmatization
Lemmatisation (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word's lemma, or dictionary form. In computational linguistics, lemmatisation is the algorithmic process of determining the lemma of a word based on its intended meaning. Unlike stemming, lemmatisation depends on correctly identifying the intended part of speech and meaning of a word in a sentence, as well as within the larger context surrounding that sentence, such as neighboring sentences or even an entire document. As a result, developing efficient lemmatisation algorithms is an open area of research.

Part Of Speech
It is a process of converting a sentence to forms – list of words, list of tuples (where each tuple is having a form (word, tag)). The tag in case of is a part-of-speech tag, and signifies whether the word is a noun, adjective, verb, and so on.
The following are the Natural Language Processing Projects, you can find the code of them in my Github Repository
Sentiment Classification
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative or neutral. A sentiment analysis system for text analysis combines natural language processing (NLP) and machine learning techniques to assign weighted sentiment scores to the entities, topics, themes and categories within a sentence or phrase.
This projects uses different datasets that contain some reviews with the respective sentiment or label ( 1 - Positive, 0 - Negative ), such as Amazon Reviews, IMDB Reviews and Yelp Reviews. The tested model was a Linear Support Vector Machine, getting an 77.6 % Accuracy. The confusion matrix for this model is the following, as you can see the performance is acceptable, with 427 samples classified correctly and 123 incorrectly. In order to improve the performance of the model you can use more complex Machine Learning Models or even Deep Learning Models.
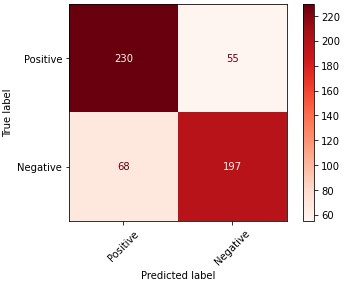
In order to test the models I created some reviews and then I passed them into the model, it's important to mention that the output 0 means a Negative Review and the output 1 a Positive Review

Link to Github Repository
Spam Text Classification
The use of mobile phones has skyrocketed in the last decade leading to a new area for junk promotions from disreptable marketers. People innocently give out their mobile phone numbers while utilizing day to day services and are then flooded with spam promotional messages. In this project I create a classifier or SMS messages using different Machine Learning models, understand why this is an important area in the Natural Language Processing. The tested models were the Random Forest and the Support Vector Machines, the last one got the best performance with 95 % accuracy classifying the Ham and Spam Messages.
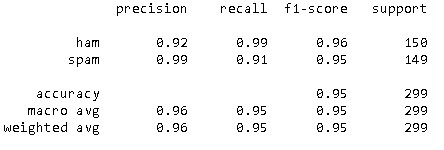
Similarly, I tested the model performance by creating some fake Messages, and the model classified them correctly.

Link to Github Repository
More Projects
Here you'll find more projects related with NLP.